在概率論和統計學中,馬可夫決策過程(英語:Markov Decision Processes,縮寫為MDPs)提供了一個數學架構模型,用於面對部份隨機,部份可由決策者控制的狀態下,如何進行決策,以俄羅斯數學家安德雷·馬爾可夫的名字命名,是馬爾科夫鏈的一種擴展。link
在經由動態規劃與強化學習以解決最佳化問題的研究領域中,MDP是一個有用的工具。廣泛應用於機器人學,自動化控制,經濟學和製造業的一種工具。
MDP的一個重要觀念:”未來只取決於當前” link
為什麼強化學習會跟MDP有關呢?我們先看什麼是State(狀態)
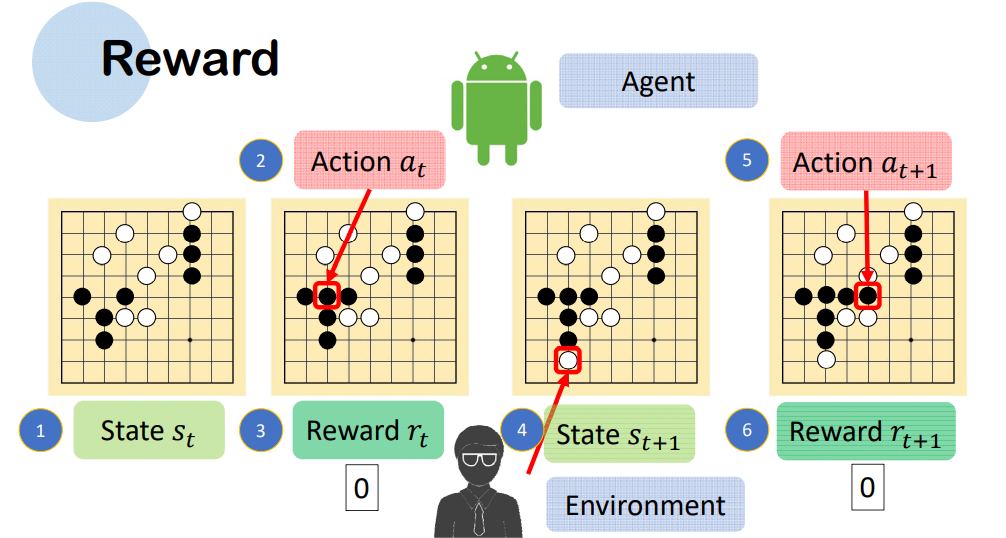
因為我們的大腦一開始並不知道環境的狀態是怎麼樣,所以只能從以前所經歷的observation,action,reward跟現在所得到的observation, reward來去當作現在的狀態
那如果我們要去估計下一個狀態(St+1)是怎麼樣的,是不是就要把S1~St的所有狀態給考慮進去,這樣模型便會非常的大,這時候Markov假說就有用了,Markov說的:未來只取決於當前,所以我們可以假設 下一個狀態只跟現在這個狀態有關,有這個假設就可以把模型給縮小,不過這個假設也只是理想的狀況下。
因此我們可以把強化學習想像成是MDP的一種模型,因為我們從現在的狀態來知道未來的狀態,未來知道了,相對的,我們要找到最好的動作也變得有可能了。所以RL就變成是解MDP的一種模型了。
強化學習(英語:Reinforcement learning,簡稱RL)是機器學習中的一個領域,強調如何基於環境而行動,以取得最大化的預期利益。 其靈感來源於心理學中的行為主義理論,即有機體如何在環境給予的獎勵或懲罰的刺激下,逐步形成對刺激的預期,產生能獲得最大利益的習慣性行為。
強化學習和標準的監督式學習之間的區別在於,它並不需要出現正確的輸入/輸出對,也不需要精確校正次優化的行為。強化學習更加專注於在線規劃,需要在探索(在未知的領域)和遵從(現有知識)之間找到平衡。
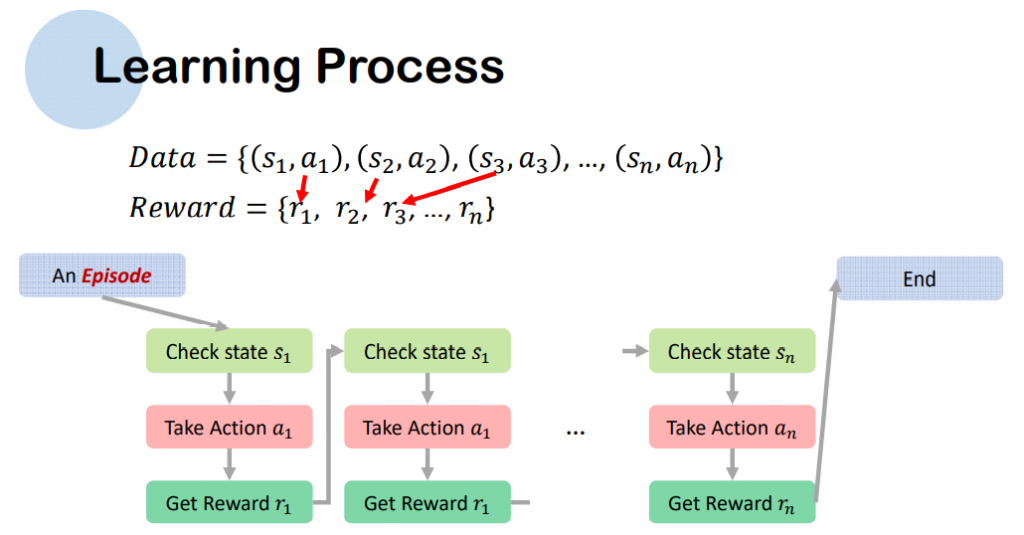
強化學習其實就是訓練一個AI 可以通過每一次的錯誤來學習,就跟我們小時候學騎腳踏車一樣,一開始學的時候會一直跌倒,然後經過幾次的失敗後,我們就可以上手也不會跌倒了。
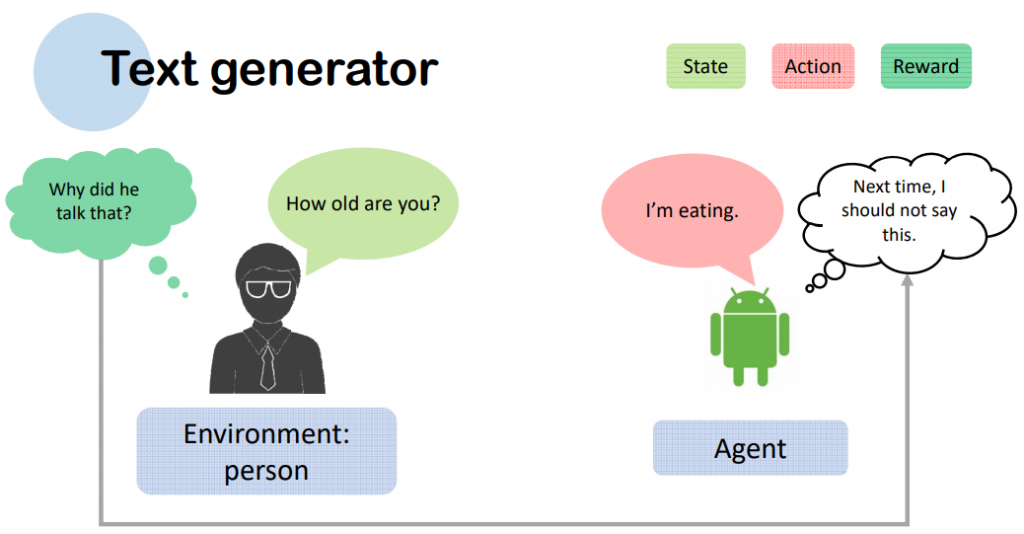
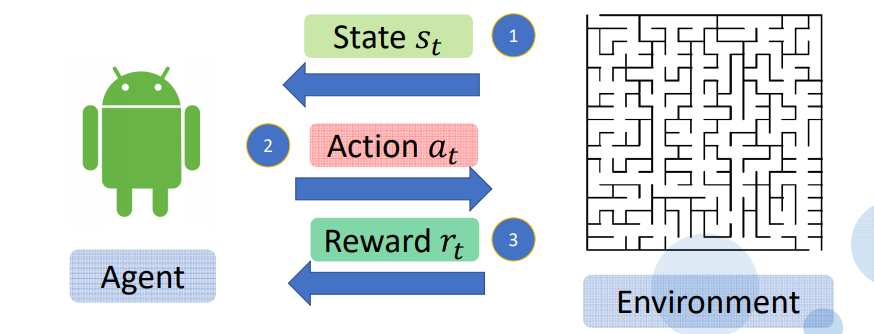
1.Agent 取得目前狀態 State St 或 Obersavation
2.Agent 採取行動 Action At
3.Enviroment (環境) 反饋 Rewards rt